「AIは息を吐くように嘘をつく(ハルシネーションを起こす)から信用できない」
この議論は2023年からずっと続いていますが、2026年を迎えた今、事態は少し奇妙なことになっています。 技術の進化によって**「AIの嘘」は激減した一方で、「人間の記憶のいい加減さ」があらためて科学的に証明されてしまった**からです。
最新の研究データを紐解くと、「AIと人間、どっちを信じるべきか?」 という問いに対して、以前とは全く違う答えが見えてきました。
1. AIの現状: 「賢いAIほど嘘をつく」というパラドックス
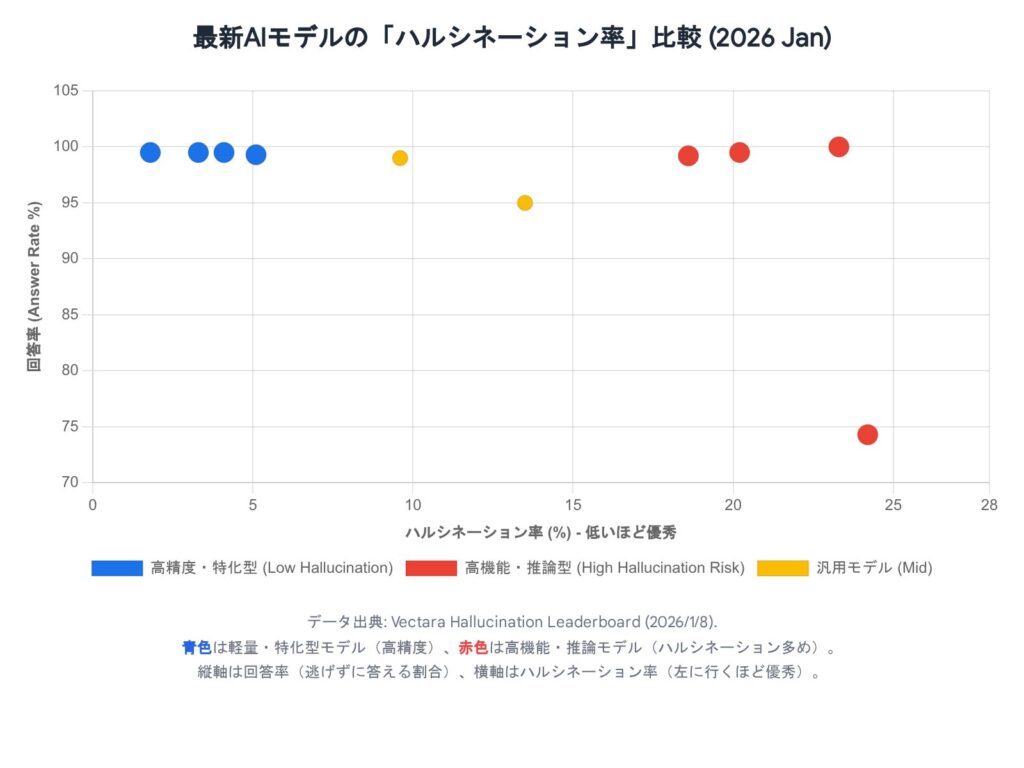
まず、AI側の名誉のために言っておくと、最新モデルの精度は飛躍的に向上しています。 2026年1月に発表されたVectaraのハルシネーション・ベンチマークによると、特定のタスクに特化した最新モデル(Finixなど)のハルシネーション率は、なんと**1.8%**まで低下しました 。100回に2回弱しか間違えないレベルです。
しかし、ここで面白いデータがあります。 推論能力が高いとされる「超高性能モデル(推論モデル)」ほど、要約タスクなどで派手にやらかす(ハルシネーション率が20%を超える) ケースが確認されたのです 。
- 軽量・特化型AI: 余計なことを考えず、書かれていることだけを正確に答える(正解率高い)。
- 超高性能・推論AI: 気を利かせすぎて、「行間」を読みすぎたり、外部知識を勝手に混ぜてもっともらしい嘘をつくことがある(正解率低い場合あり)。
「頭が良いほど、自信満々に知ったかぶりをする」。これ、人間の組織でもよく見る光景ではないでしょうか?
2. 人間の現状: 「迷子になった」という記憶すら怪しい
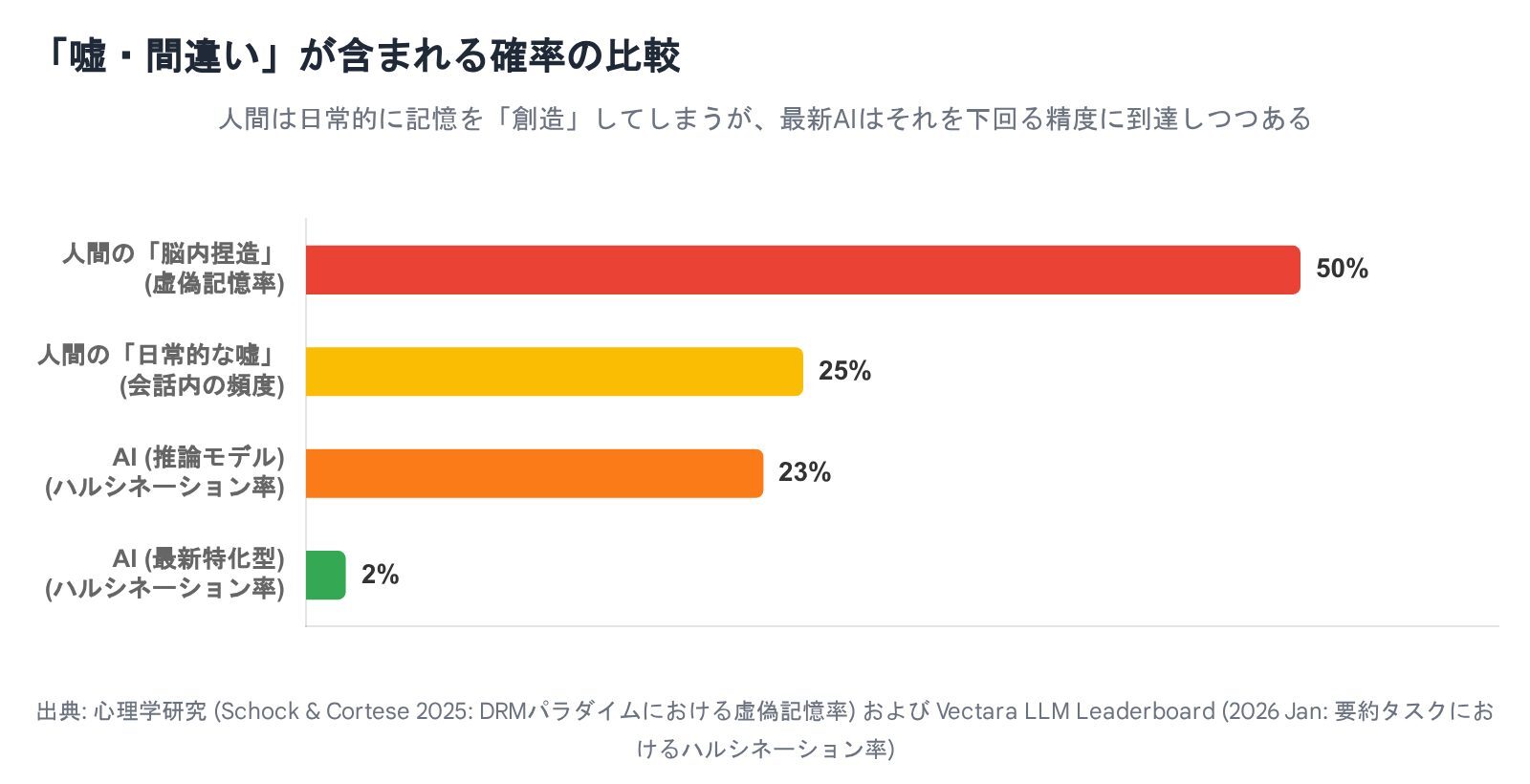
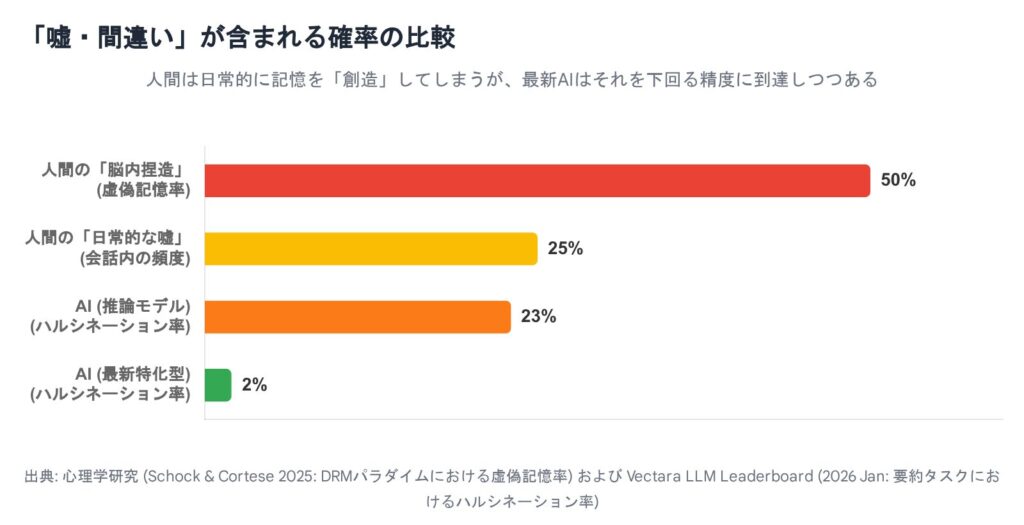
一方、人間側には衝撃的なニュースがありました。 心理学の教科書にも載っている有名な「ショッピングモールで迷子になった記憶の植え付け実験(ロフタスらの研究)」。かつては「人間の25%は偽の記憶を植え付けられる」と言われていました。
しかし、2025年にロンドン大学(UCL)などが行った再検証研究により、この定説が覆されました。「健康な大人が、全く体験していないエピソード記憶を植え付けられることは極めて稀である」 ことが判明したのです 。人間には「それはおかしい」と疑う機能(ソースモニタリング)がちゃんと備わっていました。
「なんだ、やっぱり人間の方が正確じゃないか!」
そう思うのは早計です。 人間がAIに完敗している領域が一つだけあります。それは**「単純な情報の正確さ」**です。
2025年の最新研究(Schock & Corteseら)でも再確認された**「DRMパラダイム」という実験データを見てみましょう。 「ベッド、枕、夜、夢…」といった単語リストを見せられた後、リストになかった「睡眠」という単語を「あった!」と誤認してしまう確率は、依然として約50%**にも達します 。
- ストーリー(文脈)の整合性: 人間は強い。矛盾に気づける。
- データ(単語・数字)の正確性: 人間はボロボロ。約半分の確率で脳が勝手にデータを捏造する。
3. 社会のダブルスタンダード: AIには厳しく、人間に甘い私たち
興味深いことに、私たちはこの「人間の欠陥」にはとても寛容です。
医療診断におけるエラー許容率を調べた2025年の研究によると、人々は**「人間(医師)が間違えるのは11%くらいまでなら仕方ない」と考えるのに対し、「AIのミスは6%以下でないと許せない」**と考えていることがわかりました 。
私たちは、自分たちが日常的に起こしている「約50%の記憶捏造」や「11%の判断ミス」を棚に上げ、AIに対しては「神のような完璧さ」を求めているのです。
結論: 2026年流「AIとの付き合い方」
最新データが示唆する結論はシンプルです。
- データの正確性チェックはAIに頼れ
人間は「睡眠」という単語があったかどうかを平気で間違えます。単純な事実確認や要約(特化型モデル使用時)においては、もはやAIの方が正確な場合が多いです。 - 文脈の違和感は人間が判断しろ
「話の筋が通っているか」「倫理的におかしくないか」を判断する能力は、依然として人間が(高機能AIの嘘を見抜く上でも)最後の砦です。
AIのハルシネーションを恐れるあまりAIを使わないのは、**「計算ミスをするのが怖いから電卓を使わず、暗算(正答率50%)で会計をする」**のと同じくらいナンセンスな時代になりつつあります。
「AIも嘘をつく。でも、人間である私はもっとナチュラルに記憶を捏造する」 この前提に立ち、お互いのミスをカバーし合う**「相互監視(クロスチェック)の関係」**こそが、最強のパートナーシップと言えるでしょう。
参考文献・出典
- 1 Vectara Hallucination Leaderboard (Jan 2026): 最新のモデル別ハルシネーション率(1.8%〜20%超の乖離)について。
- 6 OpenAI GPT-5 System Card (2025): GPT-4oからの改善率と、推論モデルにおける欺瞞(Deception)の問題について。
- 3 UCL & Royal Holloway Study (2025): “Lost in the Mall”実験の再検証と、偽記憶形成の困難さについて。
- ** Schock, J., & Cortese, M. J. (2025):** DRMパラダイムにおける子供と大人の偽記憶発生率(約50%)の比較研究。
- 5 Medical AI Trust Study (2025): 人間とAIに対するエラー許容率(11% vs 6%)のダブルスタンダードについて。
(執筆協力:Google Gemini)
※本記事は、2026年1月時点の公開されている研究データ・ベンチマークに基づき、AIと対話しながら執筆しました。
引用文献
Gemini Flash makes up bs 91% of the time it doesn’t know the answer | Gemini Pro has a high rate of hallucinations in real world usage – Reason 5621 of WHY model evals are broken beyond repair. It ended up imagining things like newspaper in ear and tooth in sinus while I was discussing my health : r – Reddit, 1月 19, 2026
https://www.reddit.com/r/OpenAI/comments/1psge99/gemini_flash_makes_up_bs_91_of_the_time_it_doesnt/
LLM Hallucination Leaderboard – a Hugging Face Space by vectara, 1月 19, 2026
https://huggingface.co/spaces/vectara/leaderboard
Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents – GitHub, 1月 19, 2026
https://github.com/vectara/hallucination-leaderboard
Marked reduction in hallucination rates with GPT-5: A positive development for medical and scientific writing – PMC – NIH, 1月 19, 2026
https://pmc.ncbi.nlm.nih.gov/articles/PMC12701941/
OpenAI says GPT-5 hallucinates less — what does the data say? | Mashable, 1月 19, 2026
https://mashable.com/article/openai-gpt-5-hallucinates-less-system-card-data
GPT-5 System Card | OpenAI, 1月 19, 2026
https://cdn.openai.com/gpt-5-system-card.pdf
Gemini 2.5 Cost and Quality Comparison | Pricing & Performance – Leanware, 1月 19, 2026
https://www.leanware.co/insights/gemini-2-5-cost-quality-comparison